DOMは、HTMLが持つ要素の親子関係を、ツリー構造で表現します。たとえば以下のHTMLを読み込むと…
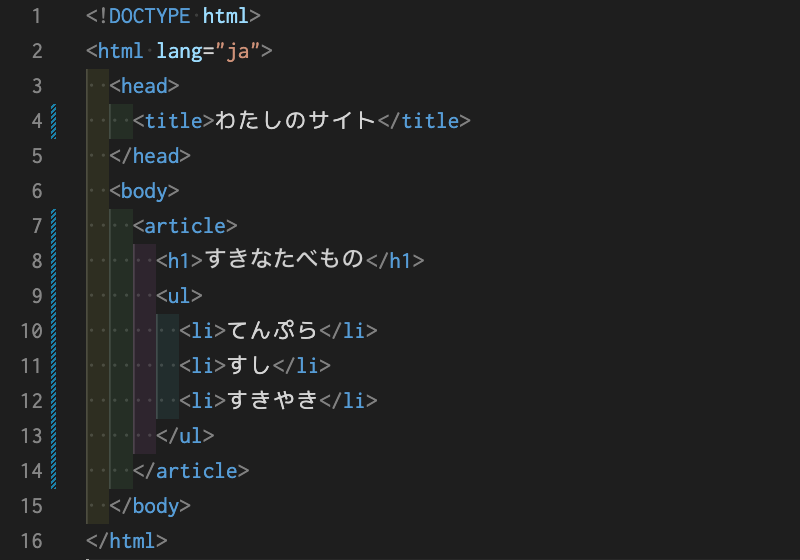
ブラウザ内部にこのようなDOM概念図が構築されます。
まず画面に表示するまでの流れはこのような感じなのですが、ここからが JavaScriptの出番です。
JavaScriptを使うと、ブラウザ内部にあるDOMにアクセスして、その内容を書き換えることができます。 DOMが書き換えられると、自動的に画面の内容が新たなDOMに合わせて再描画される仕組みになっています。
上図の一つ一つの(青や緑の)箱を、「ノード」と言います。ノードにはいくつか種類がありますが、主に「要素ノード」「テキストノード」の2種類を意識しておけば大丈夫です。 「要素ノード」は、HTML要素を表します。属性や適用されたスタイルなどの情報(プロパティ)を持っています。「テキストノード」は文字通り、要素ではなく、テキスト部分です。 次に見ていくのは、DOMから特定のノードの情報を取得する方法です。後述しますが、取得したノード情報を書き換えると、DOMにもその変更が反映されます。
ブラウザ内のJavaScriptエンジンには、基本的な文法を解析する機能のほかに、DOM操作などブラウザ固有の処理を行うためのオブジェクトがあらかじめ用意されています。 その一つがdocumentオブジェクトです。これは、HTML文書(つまり、画面に表示されているWebページ)を表すオブジェクトで、DOM操作のためのメソッドが含まれています。
では、DOM操作方法ですが、「.」を使用して記述をしていきます。 また、メソッドの戻り値がオブジェクトの場合、その戻り値を使ってさらにメソッドを呼び出すことができます。このようにメソッドを繋げて記述する方法をメソッドチェーン(メソッドカスケード)と呼びます。
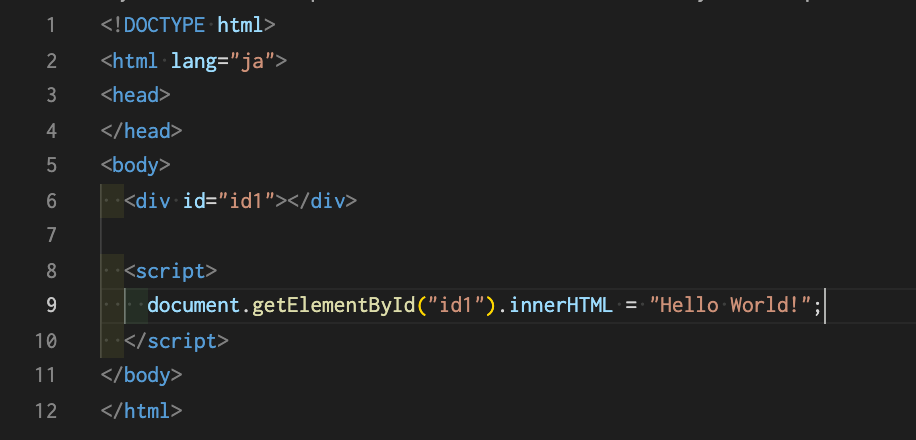
まず「getElementById」メソッドです。このメソッドは、任意のHTMLタグで指定したIDにマッチするドキュメント要素を取得するメソッドです。 引数に指定されたid属性を持つ要素ノードを、DOM全体から検索します。もし見つからなければ、nullを返します。 そのため、今回の場合だと、getElementById("id1")とのことなので、id属性が"id1"という要素を取得するというメソッドになっています。 ここで登場してきたのが("")の部分です。これは引数(パラメーター)と呼ばれ、メソッドを調整(設定)するための『値』を指定する場所です。
そして、その後に記述されているのが「innerHTML」プロパティです。これは、要素内の HTML または XML のマークアップを取得したり設定したりすることができます。 そのため、innerHTML = "Hello World!"ということなので、"id1"という要素のHTMLを"Hello World!"に設定するという記述になっています。
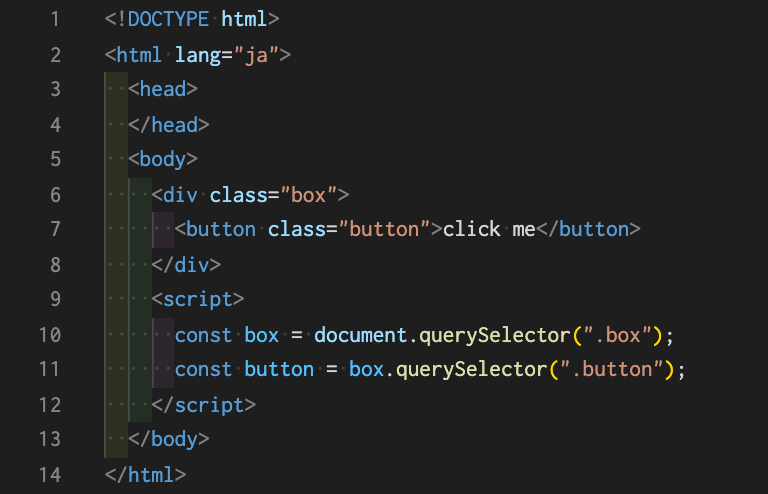
querySelectorやquerySelectorAllというメソッドを使用します。 これらのメソッドは、セレクター文字列を引数に取り、合致する要素を検索して取得します。このセレクター文字列は、CSSで用いるセレクターと同じものです。
querySelectorはgetElementByIdと同じように、単一の要素ノードを返却します。セレクターに合致する要素が文書中に複数存在する場合は、HTML的に一番上に書かれている要素が取得されます。見つからない場合は、nullを返します。
(記述例) const button = document.querySelector("#redButton");
querySelectorAllは、セレクターに合致する複数の要素を返却します。
(記述例) const buttons = document.querySelectorAll(".button");
document以外の要素に対して呼び出すと、子要素から指定のセレクターに合致する要素が検索され取得されます。
「JavaScript DOM操作」などのキーワードで検索すると、参考になる記事がたくさんヒットするでしょう。初心者の方は、書籍や、最近だと動画も含めて、いろいろな説明を吸収して、総合的に解釈するのが良いと思います。もちろん、手を動かすのも大切なのでどんどんコーディングをして力をつけていきましょう!
では次は、関数について紹介していきたいと思います。